|
 99.999%의 고가용성의 무정지 시스템 구축과 운영 메인 메모리 또는 하드디스크 기반의 고성능 데이터베이스 구현 매우 빠르고 자동적인 FailOver 시스템 유동적이고 병렬적인 분배구조 시스템 별도의 라이센스 및 제반비용이 필요없는 저렴한 구축비와 유지비 99.999%의 고가용성의 무정지 시스템 구축과 운영 메인 메모리 또는 하드디스크 기반의 고성능 데이터베이스 구현 매우 빠르고 자동적인 FailOver 시스템 유동적이고 병렬적인 분배구조 시스템 별도의 라이센스 및 제반비용이 필요없는 저렴한 구축비와 유지비 |
| MySQL-Replication 확장의 제약 : 데이터 입력 및 업데이트가 마스터서버에 의존적이기 때문에 시스템 확장시 슬레이브서버의 증설은 용이하지만 마스터서버의 증설에는 어느정도 제약이 따르게 됩니다. 클러스터 구현시 SQL-Node 의 서버군은 각 서버가 데이터 입/출력을 모두 처리하는 형태로 구현됩니다. |
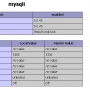
MySQL 클러스터 서버 구성을 위해서 총 3개의 서버군(Node)을 필요로 합니다.
|
 |
| Mysql-Replication은 마스터로 설정된 MySQL서버의 데이터를 슬레이브로 설정된 다수의 MySQL서버의 데이터와 동기화시켜 실시 간 백업 및 부하 분산을 위해서 사용하는 것입니다. 이를 이용해 2대의 마스터 서버를 구성해 데이터 업데이트시 각 마스터 서버에 동일하게 적용될 수 있도록 하는 기술입니다. |
| 단일 Master&Slave-Replication의 취약점 : Master서버의 장애시 마스터서버를 재구성하는 작업이 수동으로 진행됩니다. Mysql-Cluster에 비해 직관적인 사용환경 : 명시적인 파일로서 데이터가 존재하기 때문에 일부데이터를 복원 또는 기타작업시 보다 빠르고 상황에 따른 유연한 작업수행이 가능합니다. |
 |
| Master-Server 두대가 동일하게 작동하므로 서버중 한대가 Fail시 나머지 서버가 계속해서 임무 수행 각 서버에 동일한 데이터가 저장되므로 어플리케이션 접근에 의한 부하를 분산시킬 수 있습니다. |
 |
| Master-Server 중 한대는 Primary Server로서 기능을 하다가 Fail시 Standby Server가 임무를 수행 데이터 입력(Insert, Update, Delete)은 모두 마스터 서버에서 이루어지고, 데이터 불러오기(Select)는 슬레이브 서버들이 담당하게 되어 Select 쿼리가 많은 사이트에서 최적의 성능을 발휘할 수 있습니다. 실시간으로 데이터 복제가 가능하며, 서버에 거의 영향을 주지 않습니다. |